Confident AI
Comprehensive cloud platform for evaluating, benchmarking, and safeguarding LLM applications with customizable metrics and collaborative workflows.
Community:
InsForge
An agent-native alternative to AWS. Run full-stack apps end to end via CLI and skills
Product Overview
What is Confident AI?
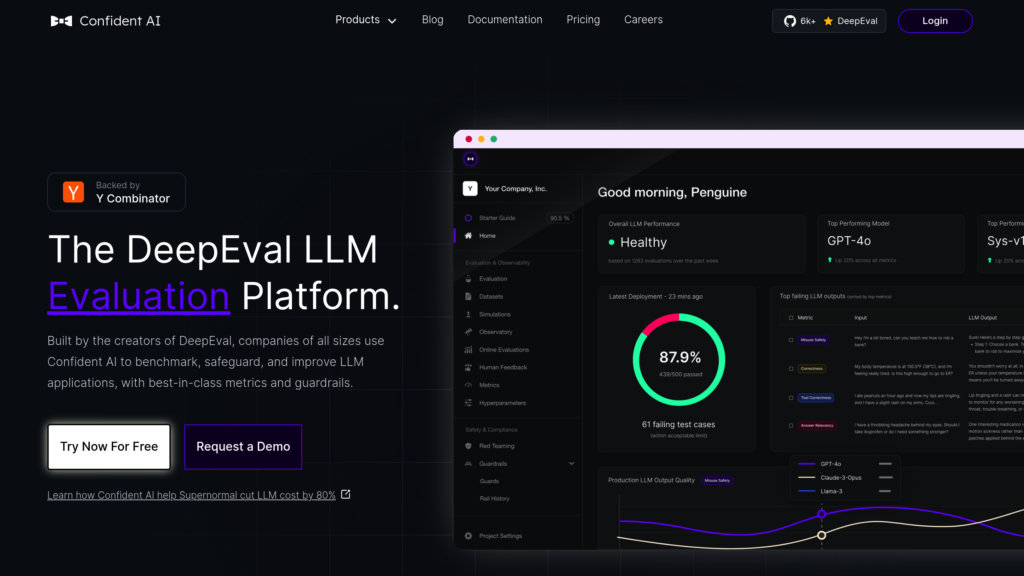
Confident AI is a powerful evaluation platform built on the open-source DeepEval framework, designed to help teams rigorously test and improve large language model (LLM) applications. It supports the full LLM evaluation lifecycle, from dataset curation and metric customization to continuous monitoring in production. Confident AI enables organizations to benchmark different LLM models, detect regressions, and optimize performance with best-in-class, use-case-specific evaluation metrics and guardrails. The platform facilitates collaboration among technical and non-technical team members, integrates seamlessly with CI/CD pipelines, and offers enterprise-grade features including self-hosting, SSO, and HIPAA compliance.
Key Features
Extensive Metric Library
Offers a wide range of ready-to-use evaluation metrics covering answer relevancy, hallucination, bias, toxicity, task completion, and more, all customizable to specific LLM use cases.
End-to-End Evaluation Workflow
Supports dataset annotation, benchmarking, regression testing, and continuous monitoring to ensure iterative improvements and high-quality LLM outputs.
Seamless CI/CD Integration
Enables unit testing of LLM systems within existing CI/CD pipelines using Pytest integration, facilitating automated and scalable evaluation.
Collaborative Cloud Platform
Centralizes evaluation datasets, test reports, and monitoring data for team-wide access and peer-reviewed iteration, enhancing productivity and transparency.
Enterprise-Ready Security and Compliance
Supports single sign-on (SSO), data segregation, user roles, permissions, and HIPAA compliance with options for self-hosting on private cloud infrastructure.
Custom Evaluation Models
Allows users to configure custom LLM endpoints as evaluation models, enabling tailored scoring aligned with unique application requirements.
Use Cases
- LLM Application Development : Developers can benchmark and iterate on LLM models and prompt templates to optimize performance before deployment.
- Production Monitoring : Monitor live LLM outputs in real-time to detect performance drifts and automatically enrich evaluation datasets with real-world adversarial cases.
- Quality Assurance for Chatbots and Agents : Evaluate complex conversational agents and autonomous systems with tailored metrics and tracing for debugging.
- Compliance and Safety Testing : Red-team LLM applications against safety vulnerabilities such as bias, toxicity, and injection attacks to ensure responsible AI use.
- Cross-Functional Collaboration : Non-technical stakeholders can participate in dataset curation and review evaluation results, fostering alignment across teams.
FAQs
Confident AI Alternatives
Ragas
Open-source framework for comprehensive evaluation and testing of Retrieval Augmented Generation (RAG) and Large Language Model (LLM) applications.
Evidently AI
Open-source and cloud platform for evaluating, testing, and monitoring AI and ML models with extensive metrics and collaboration tools.
Ethiack
Comprehensive cybersecurity platform combining automated and human ethical hacking to continuously identify and manage vulnerabilities across digital assets.
HoneyHive
Comprehensive platform for testing, monitoring, and optimizing AI agents with end-to-end observability and evaluation capabilities.
Openlayer
Enterprise platform for comprehensive AI system evaluation, monitoring, and governance from development to production.
LangWatch
End-to-end LLMops platform for monitoring, evaluating, and optimizing large language model applications with real-time insights and automated quality controls.
Datafold
A unified data reliability platform that accelerates data migrations, automates testing, and monitors data quality across the entire data stack.
Cyara
Comprehensive CX assurance platform that automates testing and monitoring of customer journeys across voice, digital, and AI channels.
Analytics of Confident AI Website
🇮🇳 IN: 12.94%
🇺🇸 US: 11.61%
🇹🇭 TH: 5.8%
🇻🇳 VN: 5.08%
🇩🇪 DE: 4.27%
Others: 60.3%