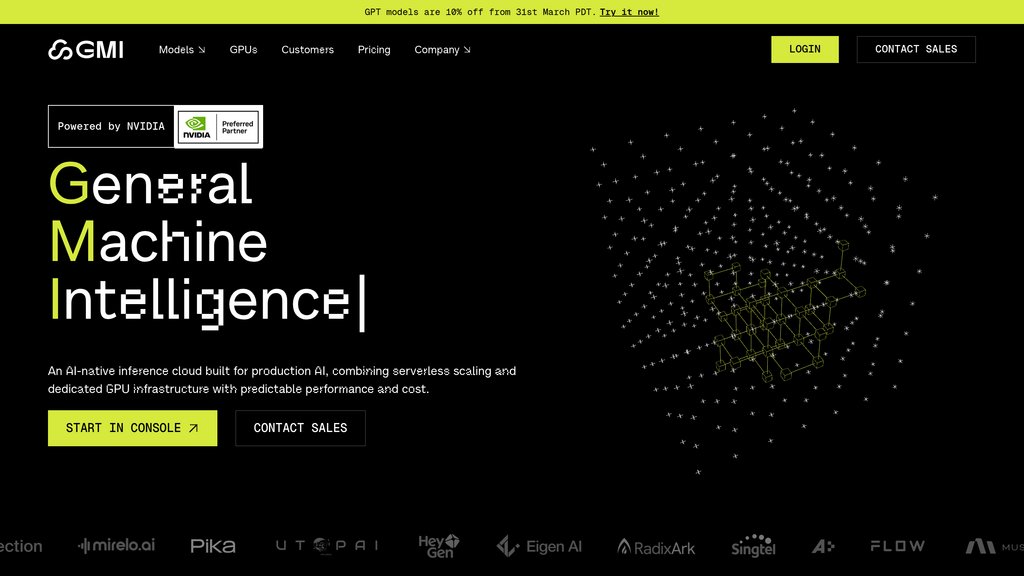
GMI Cloud
Una plataforma cloud GPU enfocada en inferencia que combina inferencia serverless e infraestructura GPU dedicada para cargas de trabajo de IA de producción, construida sobre hardware NVIDIA.
Comunidad:
Descripción del Producto
¿Qué es GMI Cloud?
GMI Cloud es una plataforma cloud nativa de IA diseñada específicamente para inferencia y entrenamiento de IA de producción. Ofrece una pila unificada que abarca inferencia serverless, orquestación de clústeres basada en Kubernetes y computación GPU bare metal — todo en GPUs NVIDIA H100, H200 y próximas Blackwell. La plataforma está diseñada para eliminar la sobrecarga típica de los hiperescaladores, recuperando el 10-15% del rendimiento GPU perdido por virtualización mientras ofrece precios transparentes de pago por uso sin cuotas ni compromisos a largo plazo. Como socio de NVIDIA Cloud, GMI Cloud proporciona acceso prioritario al hardware GPU de vanguardia con seguridad de nivel empresarial y disponibilidad global en regiones de EE.UU., UE y APAC.
Características Principales
Motor de inferencia Serverless
Despliega modelos de IA instantáneamente con escalado automático, procesamiento por lotes de solicitudes integrado y programación consciente de la latencia — incluyendo escalado a cero para eliminar costos de inactividad.
Motor de clúster GPU dedicado
Entorno de orquestación basado en Kubernetes para gestionar cargas de trabajo GPU escalables, con monitoreo en tiempo real, gestión de contenedores y aislamiento multi-inquilino seguro.
Computación GPU de alto rendimiento
Acceso bajo demanda a GPUs NVIDIA H100 y H200 con redes InfiniBand, entregando rendimiento cercano al bare metal sin restricciones de cuota ni listas de espera.
Precios de inferencia por solicitud
Más de 100 modelos pre-desplegados disponibles a tarifas por solicitud desde $0.000001 hasta $0.50/solicitud, permitiendo inferencia costo-eficiente sin contratos a largo plazo.
Seguridad y cumplimiento empresarial
Desplegado en centros de datos Tier-4 con certificaciones SOC 2 Type 1 e ISO 27001:2022, asegurando alta disponibilidad, seguridad de datos y cumplimiento regulatorio.
Casos de Uso
- Servicio LLM en tiempo real : Los equipos que ejecutan modelos de código abierto como Llama o DeepSeek pueden servirlos con latencia ultra-baja con escalado automático de tráfico a través del motor de inferencia.
- Entrenamiento de IA a gran escala : Los equipos de investigación e ingeniería pueden ejecutar trabajos de entrenamiento distribuido en clústeres GPU multi-nodo con redes InfiniBand listas para RDMA para máximo rendimiento.
- Infraestructura para startups de IA : Los equipos en etapa temprana pueden comenzar serverless con cero costo inicial, luego migrar a infraestructura GPU dedicada a medida que crecen las cargas de trabajo de producción — sin re-arquitectura.
- Despliegue de IA empresarial : Las empresas que requieren rendimiento predecible, cumplimiento y control de costos pueden aprovechar GPUs bare metal dedicadas con descuentos basados en compromiso.
- Inferencia de modelos multimodales : Las APIs listas para producción soportan despliegues tanto de LLM como de modelos multimodales, cubriendo una amplia gama de cargas de trabajo de inferencia desde generación de texto hasta tareas de visión.
Preguntas Frecuentes
Alternativas a GMI Cloud
Fluidstack
Plataforma cloud que proporciona infraestructura GPU rápida y a gran escala para entrenamiento e inferencia de modelos de IA, en la que confían laboratorios y empresas líderes en IA.
Cerebrium
Plataforma de infraestructura de IA sin servidor que permite el despliegue y la gestión rápidos y escalables de modelos de IA con rendimiento y eficiencia de costos optimizados.
FuriosaAI
Aceleradores de IA de alto rendimiento y eficiencia energética diseñados para inferencia escalable en centros de datos, optimizados para grandes modelos de lenguaje y cargas de trabajo multimodales.
Not Diamond
Router de meta-modelos de IA que selecciona inteligentemente el modelo de lenguaje grande (LLM) óptimo para cada consulta, maximizando la calidad, reduciendo el costo y minimizando la latencia.
Cirrascale Cloud Services
Plataforma cloud de alto rendimiento que ofrece computación y almacenamiento escalables acelerados por GPU, optimizados para cargas de trabajo de IA, HPC y generativas.
Unify AI
Una plataforma que simplifica el acceso, comparación y optimización de modelos de lenguaje grande mediante una API unificada y enrutamiento dinámico.
Inferless
Plataforma de GPU sin servidor que permite el despliegue rápido, escalable y eficiente de modelos personalizados de aprendizaje automático con autoescalado y baja latencia.
Predibase
Plataforma de IA de nueva generación especializada en el ajuste fino y despliegue de modelos de lenguaje pequeños open-source con velocidad y eficiencia de costos incomparables.
Analítica del Sitio Web de GMI Cloud
🇺🇸 US: 18.23%
🇹🇼 TW: 9.88%
🇮🇳 IN: 8.8%
🇹🇭 TH: 3.94%
🇧🇷 BR: 3.32%
Others: 55.83%