产品概览
什么是URLtoText?
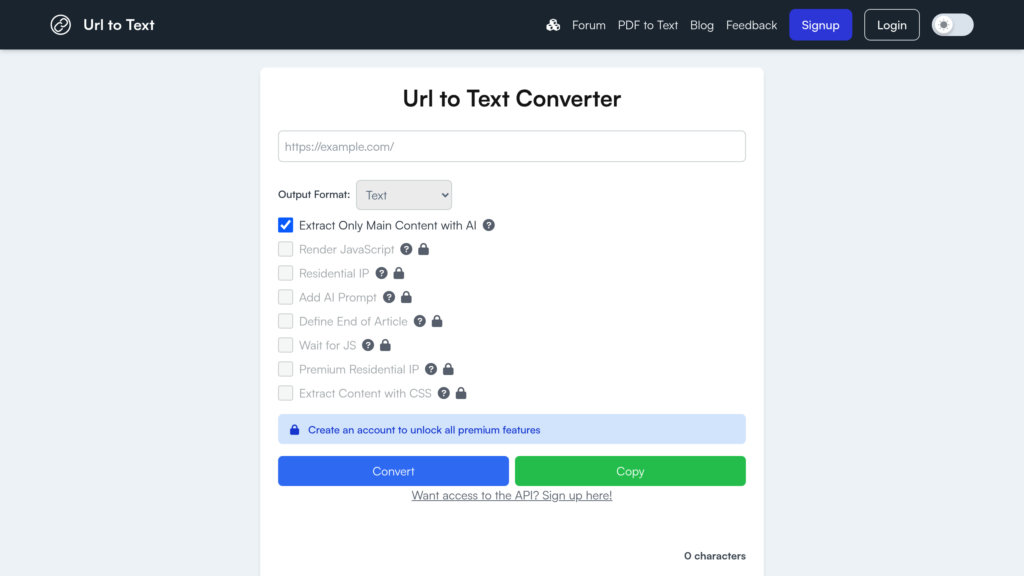
URLtoText 是一个简单易用的在线平台,可将任意有效网页URL转换为干净的文本或Markdown格式。支持复杂网站结构,包括大量JavaScript页面,并提供AI Prompt集成及住宅IP选项以绕过反爬虫措施。最初作为AI训练用高效网页抓取工具的测试界面开发,如今已成为免费、可靠的文本提取工具,无需编程即可快速获取干净文本。未来将推出付费方案和API接口,满足更高需求和可扩展性。
主要功能
纯文本与Markdown输出
可从任意网站提取可读的纯文本或Markdown格式内容,选择Markdown时会保留基础格式。
支持JavaScript渲染
可处理大量依赖JavaScript的网站动态内容,确保完整文本提取。
住宅代理选项
通过住宅IP地址绕过部分网站的验证码和反爬虫保护。
AI Prompt集成
允许用户为提取内容添加AI提示词,便于直接输入到AI工具。
简洁易用的界面
只需输入网址并选择格式,即可快速提取文本,操作简单。
即将上线API接口
计划为开发者提供强大的API,便于将URLtoText能力集成到各类应用中。
使用场景
- AI内容提取 : 用户可从网站提取干净文本,直接用于AI模型分析、摘要或进一步处理。
- 科研与数据挖掘 : 研究人员可高效收集多来源网页文本,无需手动复制粘贴。
- 内容再利用 : 市场人员和写作者可快速获取网页文本,用于改写、翻译或内容创作。
- 无障碍阅读与文本整理 : 将杂乱网页转为干净、无干扰的文本,方便阅读或离线使用。
- 网页抓取测试 : 开发者可先测试单个URL的提取效果,再扩展到批量爬取。
常见问题
URLtoText的替代方案
Askpot
一款快速直观的竞争分析工具,从网站提取关键洞察以简化市场研究和商业策略。
WebScraping.AI
全面的网络抓取API,管理代理、浏览器、验证码和HTML解析,轻松提供干净、结构化的网络数据。
Tabstack
面向 AI Agent 的 Web 执行和数据转换 API,提供提取、研究和自动化端点,具有 Mozilla 支持的隐私保护。
Zyte
具备高级反封禁、代理管理和可扩展能力的AI驱动网页采集API与数据提取平台。
Firecrawl
面向开发者的API,通过可扩展的爬取和抓取,将整站内容转化为结构化、适用于大模型的格式。
Oxylabs
业界领先的代理与网页数据采集平台,提供海量IP资源与AI驱动采集方案,实现可扩展、无阻碍的数据收集。
HARPA AI
集成多种AI模型的全能浏览器扩展,实现网页自动化、内容创作和实时交互。
ScrapeGraphAI
AI驱动的网页爬取库,结合大型语言模型与图流程,实现灵活多格式数据提取。
URLtoText网站分析
🇺🇸 US: 20.31%
🇮🇳 IN: 15.72%
🇳🇬 NG: 7.57%
🇻🇳 VN: 6.29%
🇬🇧 GB: 4.48%
Others: 45.63%