產品概覽
Confident AI 是什麼?
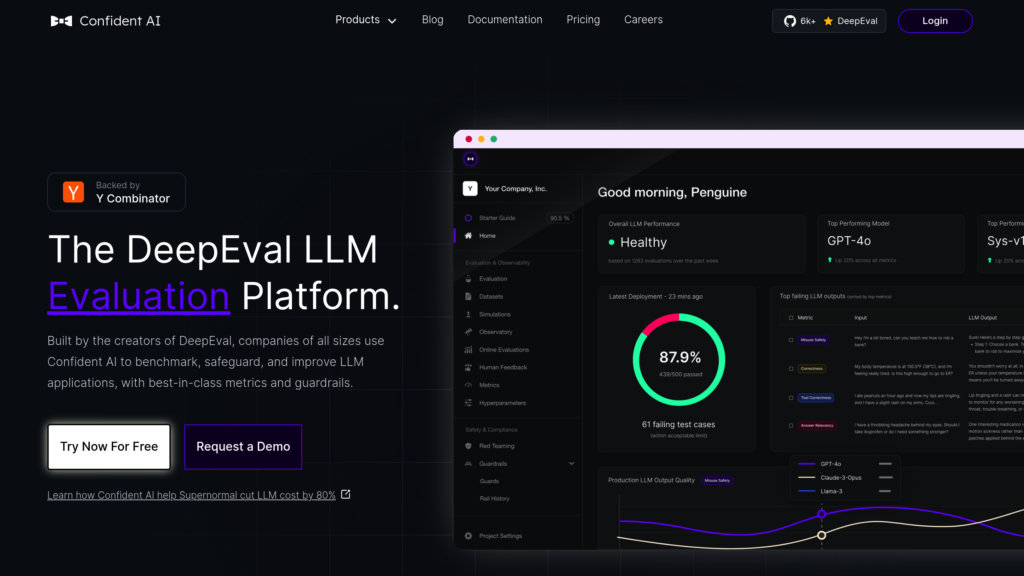
Confident AI 為基於開源 DeepEval 框架打造的強大評測平台,協助團隊嚴謹測試與優化大型語言模型(LLM)應用。從資料集建立、指標自訂到生產環境持續監控,完整覆蓋LLM評測生命週期。Confident AI 讓組織能夠比較不同LLM模型、偵測回歸、並以業界最佳指標與防護措施,針對不同應用場景優化效能。平台促進技術與非技術人員協作,無縫整合CI/CD流程,並提供企業級功能如自架部署、SSO與HIPAA合規。
主要功能
豐富的評估指標庫
提供多樣化、可即時使用的評估指標,涵蓋答案相關性、幻覺、偏見、有害內容、任務完成度等,並可依不同LLM應用場景自訂。
端到端評測流程
支援資料集標註、基準測試、回歸測試與持續監控,確保LLM產出品質隨時優化。
無縫CI/CD整合
可透過Pytest整合,讓LLM系統在既有CI/CD流程中進行單元測試,實現自動化與規模化評估。
協作雲端平台
集中管理評測資料集、測試報告與監控數據,團隊成員皆可存取與互評,提高生產力與透明度。
企業級安全與合規
支援單一登入(SSO)、資料隔離、使用者角色與權限管理,並符合HIPAA合規要求,亦可選擇私有雲自架部署。
自訂評估模型
允許用戶設定自有LLM endpoint作為評估模型,打造符合應用需求的專屬評分機制。
使用案例
- LLM應用開發 : 開發者可針對LLM模型與提示模板進行基準測試與優化,提升部署前的效能。
- 生產環境監控 : 即時監控LLM產出,偵測效能漂移,並自動收集真實世界對抗案例以豐富評測資料集。
- 聊天機器人與智能代理品質保證 : 針對複雜對話式智能代理與自主系統,提供專屬指標與追蹤功能,協助除錯。
- 合規與安全測試 : 針對LLM應用進行紅隊測試,檢查偏見、有害內容與注入攻擊等安全風險,確保負責任AI應用。
- 跨部門協作 : 非技術成員也能參與資料集建立與評測結果審查,促進團隊對齊。
常見問題
Confident AI 的替代方案
Ragas
專為RAG(檢索增強生成)與LLM應用打造的開源評測與測試框架,功能全面。
Evidently AI
開源與雲端平台,提供豐富指標與協作工具,專為AI與ML模型評估、測試、監控而設計。
Ethiack
全面的網路安全平台,結合自動化和人工道德駭客,持續識別和管理數位資產中的漏洞。
HoneyHive
全面的平台,用於測試、監控和最佳化AI Agent,具備端對端可觀測性和評估能力。
Openlayer
企業平台,用於從開發到生產的全面AI系統評估、監控和治理。
LangWatch
端到端 LLMops 平台,提供即時監控、評估與優化大型語言模型應用,具備自動品質控管與即時洞察功能。
Datafold
一個統一的資料可靠性平台,可加速資料遷移,自動化測試,並監控整個資料堆疊的資料品質。
Cyara
全面的CX保障平台,自動化測試和監控跨語音、數位和AI管道的客戶旅程。
Confident AI 網站分析
🇮🇳 IN: 12.94%
🇺🇸 US: 11.61%
🇹🇭 TH: 5.8%
🇻🇳 VN: 5.08%
🇩🇪 DE: 4.27%
Others: 60.3%