Pioneer AI
Plateforme d'ajustement fin Agent pour SLM et LLM avec configuration en un clic, inférence adaptative et amélioration continue des modèles.
Communauté:
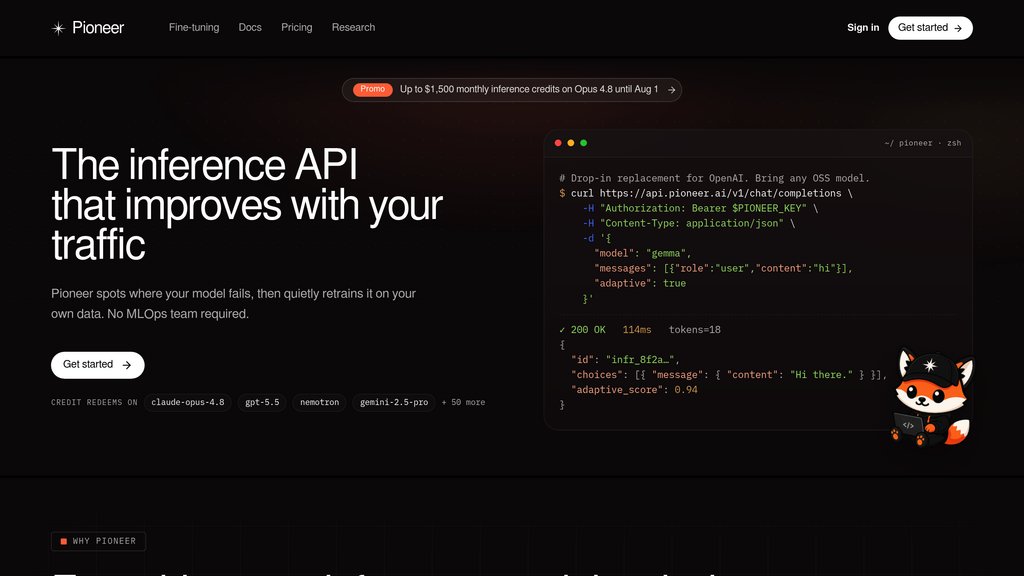
Aperçu du produit
Qu'est-ce que Pioneer AI ?
Pioneer AI est le premier Agent au monde pour l'ajustement fin et l'inférence de modèles de langage petits (SLM) et grands (LLM) open source. Développé par Fastino Labs, la plateforme permet aux équipes d'ajuster fin et de déployer des modèles comme Qwen, Gemma, Llama et GLiNER pour atteindre des performances de pointe en minutes avec un seul prompt. Une fois déployés sur l'inférence production de Pioneer, les modèles s'optimisent continuellement par rapport aux données d'inférence en direct, s'améliorant automatiquement au fil du temps sans intervention manuelle. La plateforme ne nécessite pas d'infrastructure MLOps et rend la construction de modèles prêts pour la production accessible à toute équipe sans expertise en apprentissage automatique.
Fonctionnalités clés
Ajustement fin en un clic
Décrivez votre tâche en français simple et Pioneer génère automatiquement des données d'entraînement synthétiques, sélectionne les hyperparamètres, entraîne sur des GPU cloud, évalue par rapport aux benchmarks et déploie le modèle — l'ensemble du processus en seulement 10 minutes.
Inférence adaptative
Les modèles déployés surveillent continuellement les données d'inférence en direct, identifient les modèles d'échec et entraînent automatiquement des points de contrôle améliorés avec des corrections ciblées, garantissant que les modèles s'améliorent au fil du temps sans intervention humaine.
Modes Agent et Recherche
Le mode Agent fournit un contrôle de dialogue itératif pour les ensembles de données, les étiquettes de classe et les hyperparamètres ; le mode Recherche exécute un ajustement fin entièrement autonome avec navigation web, exécutant des expériences parallèles pour trouver la meilleure configuration.
Support des modèles open source
Supporte les principaux modèles OSS incluant Llama 3, Qwen, DeepSeek, Gemma et GLiNER2 — un encodeur de 205M paramètres correspondant à GPT-4o sur les benchmarks NER tout en s'exécutant en moins de 100ms sur CPU.
API d'inférence haute performance
API de qualité production avec 99,99% de disponibilité, compatibilité native OpenAI et Anthropic, mise en cache des prompts pour économiser les coûts et service à haut débit pour les charges de travail réelles.
Export des poids du modèle
Le tier Pro inclut les poids de modèle téléchargeables pour l'inférence locale et l'auto-hébergement, permettant aux équipes d'exécuter les modèles hors ligne ou sur leur propre infrastructure.
Cas d'utilisation
- Classification des intentions : Les équipes de service client et de support peuvent déployer des SLM ajustés fins pour atteindre une précision de 99,3% sur les tâches de classification d'intentions à une fraction du coût des modèles de pointe.
- Reconnaissance d'entités nommées : Les flux de travail d'extraction de données et de traitement de texte bénéficient de l'ajustement fin GLiNER2, correspondant à GPT-4o sur les benchmarks NER avec une taille de modèle 500 fois plus petite et une inférence CPU uniquement.
- Génération de code : Les équipes de développement personnalisent les modèles pour des tâches de codage spécifiques, des langages ou des frameworks, réalisant une précision supérieure par rapport aux modèles généralistes de pointe.
- Extraction de texte et détection de spam : Les cas d'usage d'automatisation commerciale réalisent un F1 de 0,997 sur la détection de spam et une extraction de texte haute précision à partir de documents non structurés.
- Raisonnement mathématique et résumé : Modèles spécialisés pour la documentation technique, le contenu éducatif et les tâches de résumé de recherche avec une précision ajustée fine sur le contenu spécifique au domaine.
- Flux de travail Agent AI : Construisez des architectures hybrides utilisant les LLM pour le raisonnement/la planification et les SLM ajustés fins pour les tâches à haut volume et faible latence nécessitant une précision déterministe.
FAQ
Alternatives à Pioneer AI
Humain
Plateforme native IA complète fournissant des solutions d'infrastructure IA, de cloud, de données, de modèles et d'applications de bout en bout.
Crusoe Cloud
Plateforme d'infrastructure cloud IA éco-énergétique combinant centres de données alimentés par énergies renouvelables avec calcul GPU optimisé et services d'inférence gérés pour déploiement accéléré de modèles.
LangChain
Un framework composable pour créer, exécuter et gérer des applications propulsées par des grands modèles de langage (LLM) avec des outils avancés pour les workflows, l’orchestration et l’observabilité.
Unsloth AI
Plateforme open source accélérant l'affinage des grands modèles de langage avec jusqu'à 32x de rapidité et une réduction de l'utilisation mémoire.
Cerebras
Plateforme d'accélération IA offrant une vitesse record pour le deep learning, l'entraînement de LLM et l'inférence via des processeurs à l'échelle de la tranche et le supercalculateur cloud.
Mastra
Framework open-source TypeScript pour créer des applications IA avancées avec agents modulaires, workflows et intégrations.
Hailo
Spécialiste du calcul en périphérie développant des processeurs haute performance qui permettent l'inférence d'apprentissage automatique en temps réel directement sur les appareils.
Arcee AI
Un laboratoire d'intelligence ouverte basé aux États-Unis construisant des modèles de langage à poids ouverts efficaces qui fonctionnent sur edge, on-prem ou cloud sans verrouillage fournisseur.
Analytiques du site Pioneer AI
🇺🇸 US: 26.21%
🇨🇳 CN: 23.96%
🇹🇼 TW: 14.97%
🇭🇰 HK: 12.62%
🇯🇵 JP: 3.61%
Others: 18.62%